NeurIPS 2025
 27
27
27
I'm Randall Balestriero — an AI researcher building the theoretical foundations of world models, self-supervised learning, and learnable signal processing for time-series. A decade of research (Rice · Meta FAIR · Citadel) turning rigorous theory into systems that improve the state of the art on vision, NLP, geophysics, bioacoustics, medical signals, and quantitative finance.
We are putting one AI on every desk and in every home. That puts intense pressure on practitioners to deliver empirical breakthroughs, and on regulators to safeguard users. I work across the full pipeline — data, architecture, loss, and time-series structure — so that the next generation of world models is self-contained, provably safe, and energy-efficient.
Learning predictive latent dynamics of the world that let agents perceive, imagine, plan, and act. Joint Embedding Predictive Architectures (JEPA), energy-based world models, and the theoretical building blocks that make them provably sample-efficient and safe.
A decade of learnable signal processing — parametrized wavelets, deep wavelet transforms, and structured operators for high-dimensional, non-stationary signals. Deployed in NASA's Mars SEIS, bioacoustics, geophysics, medical signals, and quantitative finance.
Provable foundations for SSL — augmentation, contrastive and joint-embedding losses, and the geometry of learned representations. Co-author of Meta's Cookbook of Self-Supervised Learning with Yann LeCun.
Reading deep networks as continuous piecewise-affine spline operators — turning geometry into practical wins on batch-norm, generative networks, inversion, and beyond.
Quantifying and removing dataset biases from trained generative networks — without retraining — and providing the theoretical answers regulators need as AI scales.
Practical theory for noisy, non-stationary domains: quantitative finance (Citadel · GQS), medical data, and large-scale generative AI.
Ten years connecting signal processing, geometry, and deep learning — across academia, industry, and a NASA mission.
Three back-to-back appearances on Machine Learning Street Talk on JEPA-style world models, the geometry of neural networks, and how to build specialist LLMs without massive pretraining.
Bringing first-principles representation learning and forecasting to one of the hardest real-world time-series domains: highly noisy, non-stationary financial signals. Industry exposure that sharpens the research agenda toward practical, deployable theory.
Broadened my research to self-supervised learning and the biases that emerge from augmentation and regularization — leading to publications, an ICML tutorial, and Meta's SSL Cookbook.
Developed the affine spline operator view of deep networks, then used it to revisit batch-normalization and generative networks — turning theory into empirical wins.
Early work on learnable parametrized wavelets, later extended to deep wavelet transforms — deployed in NASA's Mars SEIS mission for marsquake detection.
A few highlights — for the full record see the live BibTeX index further down or Google Scholar.
27
 11
11
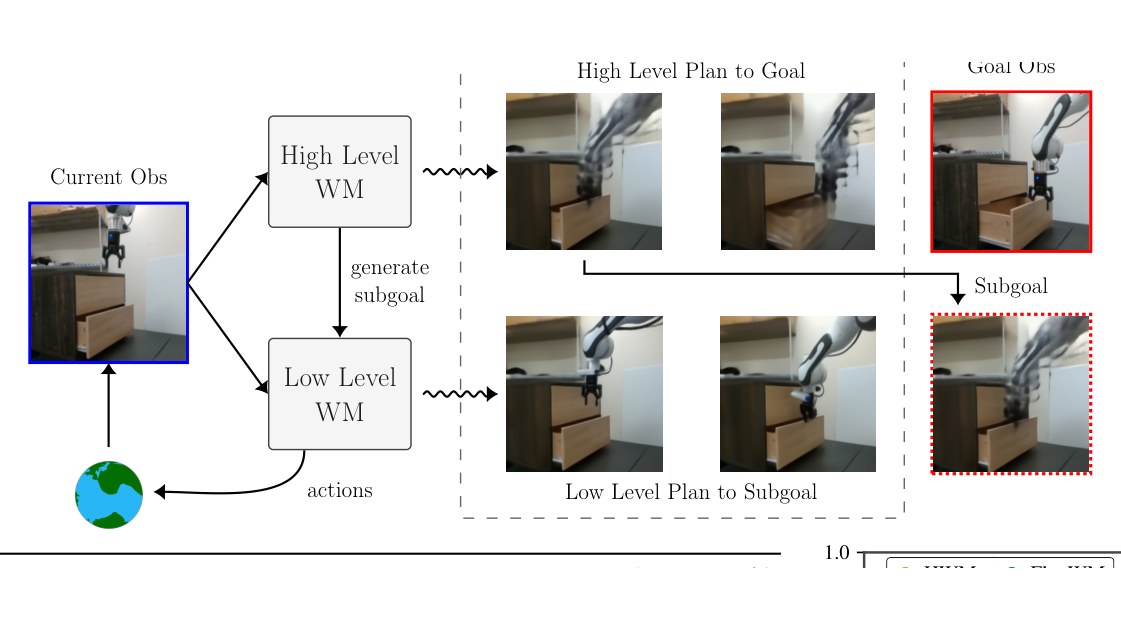
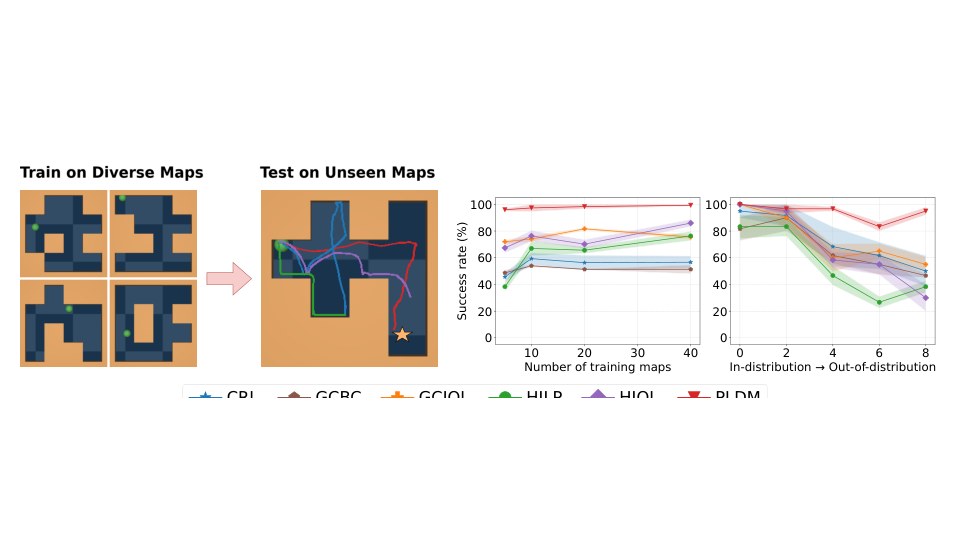
Latent world models learned at multiple temporal scales — enabling zero-shot, long-horizon robotic control (70% pick-and-place success vs 0% for single-scale baselines).
 19
19
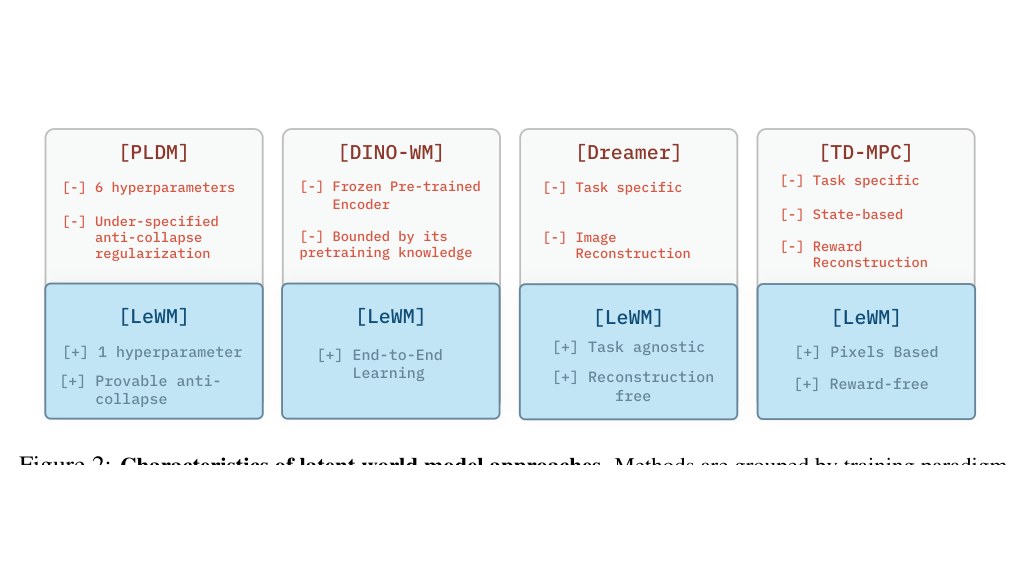
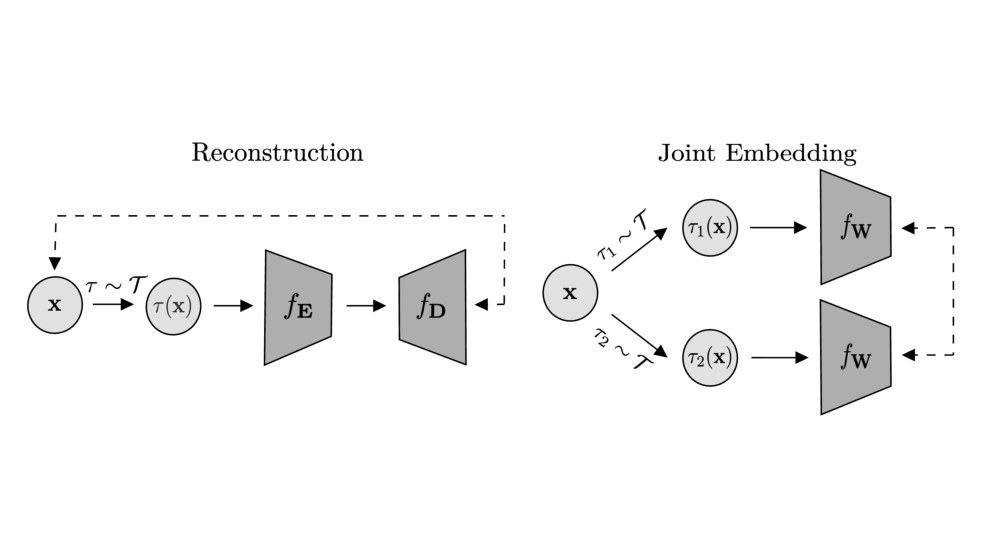
Closed-form analysis of when JEPA wins over reconstruction: latent prediction is strictly preferred when irrelevant features dominate the input signal.
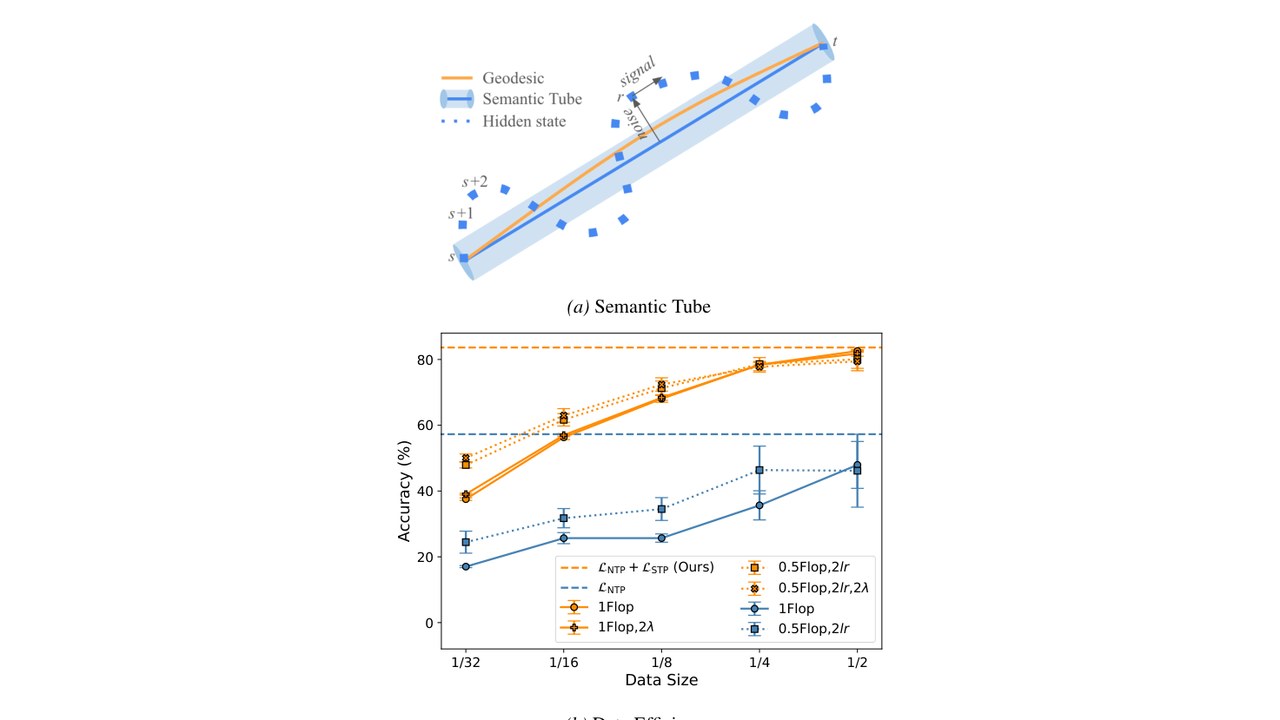
Extending JEPA to language. Constrains hidden trajectories to a tube around the geodesic — drastically reducing the data needed to fine-tune LLMs. With Huang and LeCun.
 705
705
 68
68
 266
266
Deep wavelet representations for time-series — deployed in NASA's Mars SEIS mission for marsquake detection. Demonstrates learnable signal processing at the scale of real geophysical data.
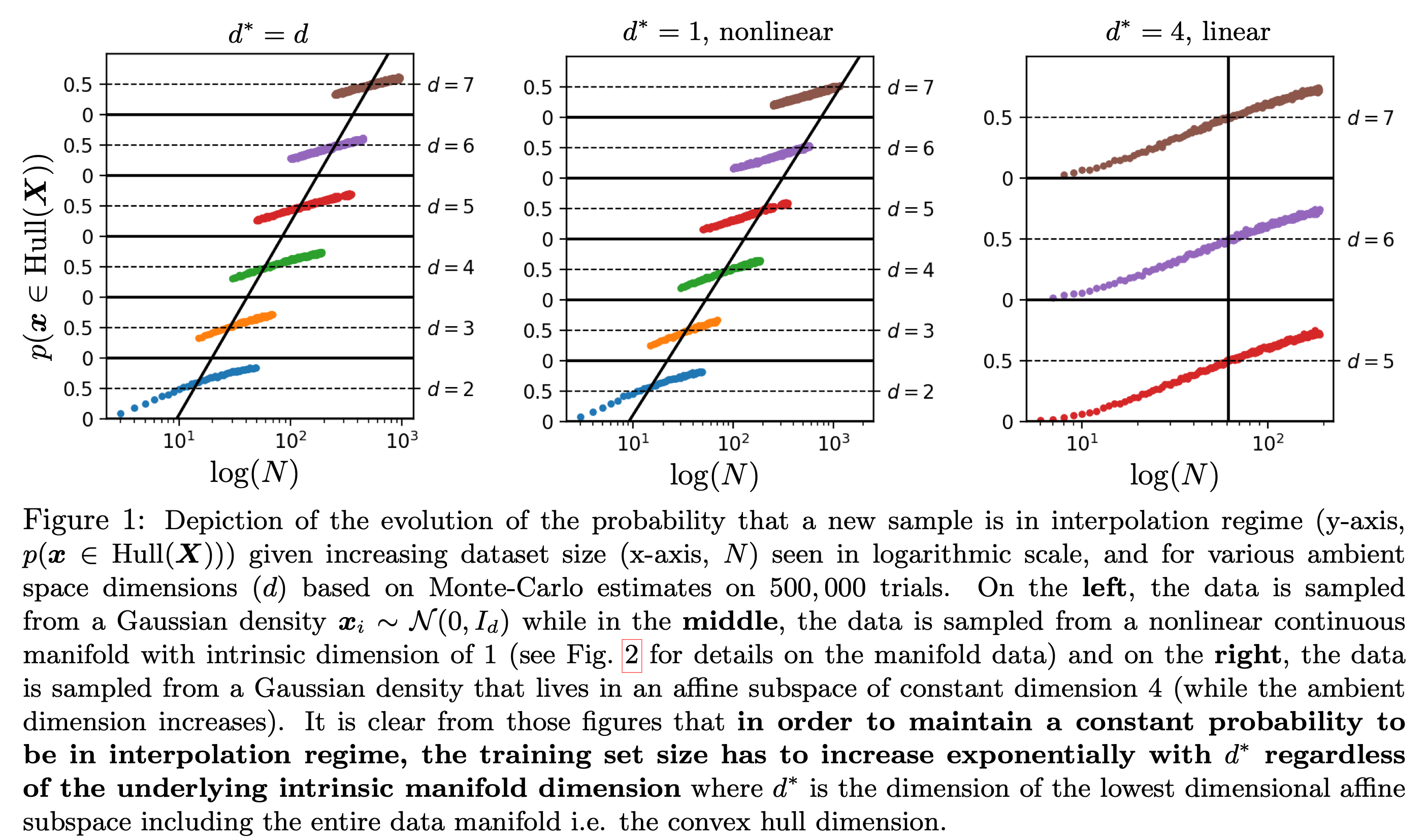 185
185





Long-form conversations on world models, self-supervised learning, the geometry of deep nets, and the future of LLMs — plus press coverage from Meta AI, Rice, NYU, and IEEE.

Joint Embedding Predictive Architectures — the world-model paradigm Yann LeCun and I have been pushing forward at FAIR.

Counter-intuitive results: 7B-parameter LLMs can match pretrained baselines when trained from scratch on small task-specific corpora. A unified view of SSL and supervised learning.

The geometry of deep networks via spline theory — grokking, intrinsic dimensionality, toxicity detection, and what RLHF actually does to representations.

A long-form NeurIPS 2022 conversation on the future of self-supervised learning, the limits of reward signals, and the path to autonomous AI.

Why "interpolation" doesn't mean what you think in high dimensions — and what that implies for generalization in modern deep nets.
ICML 2023 tutorial co-presented at the conference — the practical and theoretical state of SSL, with the FAIR Cookbook as companion.



Interested in world models, SSL, or theory of deep learning — or hiring? I'd love to hear from you.